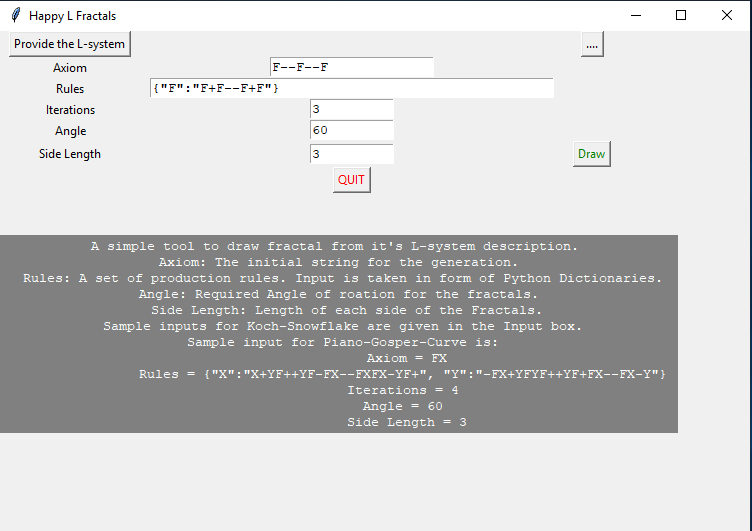
Simply out of boredom I have developed a very simple application to draw fractals from the L-system description. I am fascinated by their structure and elegance. But, unfortunately, I am not going to discuss fractals and L-system in this blog. There are many good sources to learn about those on the web.
I am here just to introduce the tool. To see the tool in action please watch the video.
Download the tool from GitHub.
Dependencies
Python 3.0 or above
Tkinter
Turtle
Input Description
Axiom: The initial string for the generation.
Rules: A set of production rules. Rules are taken in form of Python Dictionaries.
Angle: Required Angle of rotation for the fractals.
Side Length: Length of each side of the Fractals.
Sample input for Piano-Gosper-Curve is:
Axiom = FX
Rules = {"X":"X+YF++YF-FX--FXFX-YF+", "Y":"-FX+YFYF++YF+FX--FX-Y"}
Iterations = 4
Angle = 60
Side Length = 3"
Sample Interface