 |
| Add caption |
The variational autoencoder or VAE is a directed graphical generative model which has obtained excellent results and is among the state of the art approaches to generative modeling. It assumes that the data is generated by some random process, involving an unobserved continuous random variable z. it is assumed that the z is generated from some prior distribution P_θ(z) and the data is generated from some condition distribution P_θ(X|Z), where X represents that data. The z is sometimes called the hidden representation of data X.
Like any other autoencoder architecture, it has an encoder and a decoder. The encoder part tries to learn q_φ(z|x), which is equivalent to learning hidden representation of data X or encoding the X into the hidden representation (probabilistic encoder). The decoder part tries to learn P_θ(X|z) which decoding the hidden representation to input space. The graphical model can be expressed as the following figure.


The model is trained to minimize the objective function

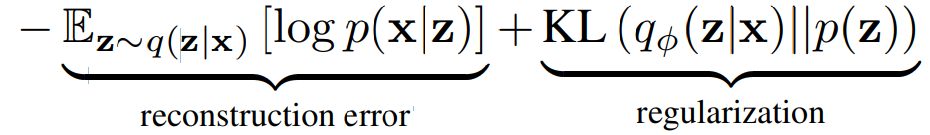
The first term in this loss is the reconstruction error or expected negative log-likelihood of the datapoint. The expectation is taken with respect to the encoder’s distribution over the representations by taking a few samples. This term encourages the decoder to learn to reconstruct the data when using samples from the latent distribution. A large error indicates the decoder is unable to reconstruct the data.
The second term is the Kullback-Leibler divergence between the encoder’s distribution q_φ(z|x) and p(z). This divergence measures how much information is lost when using q to represent a prior over z and encourages its values to be Gaussian.
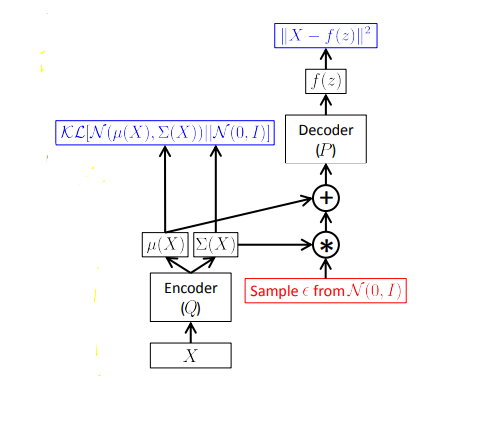
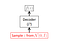
During generation, samples from N(0,1) is simply fed into the decoder. The training and the generation process can be expressed as the following
The reason for such a brief description of VAE is, it is not the main focus but very much related to the main topic.
The one problem for generating data with VAE is we do not have any control over what kind of data it generates. For example, if we train a VAE with the MNIST data set and try to generate images by feeding Z ~ N(0,1) into the decoder, it will also produce different random digits. If we train it well, the images will be good but we will have no control over what digit it will produce. For example, you can not tell the VAE to produce an image of digit ‘2’.
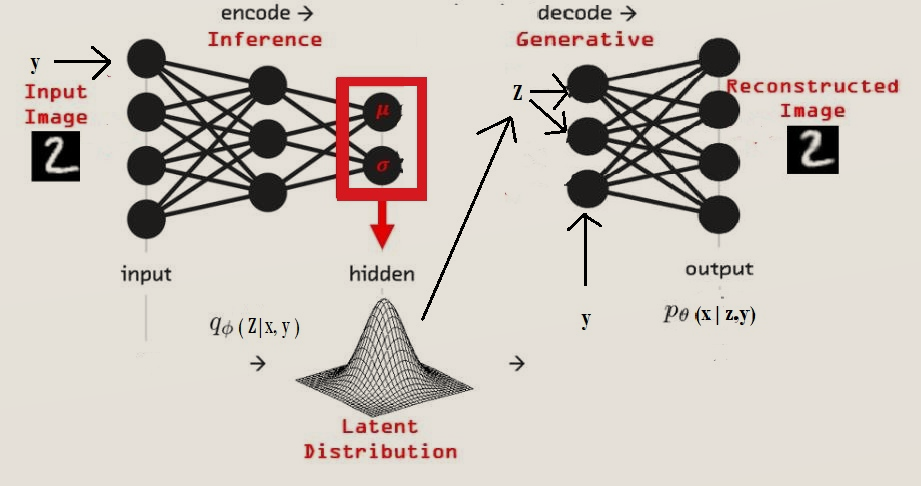
For this, we need to have a little change to our VAE architecture. Let’s say, given an input Y(label of the image) we want our generative model to produce output X(image). So, the process of VAE will be modified as the following: given observation y, z is drawn from the prior distribution P_θ(z|y), and the output x is generated from the distribution P_θ(x|y, z). Please note that, for simple VAE, the prior is P_θ(z) and the output is generated by P_θ(x|z).

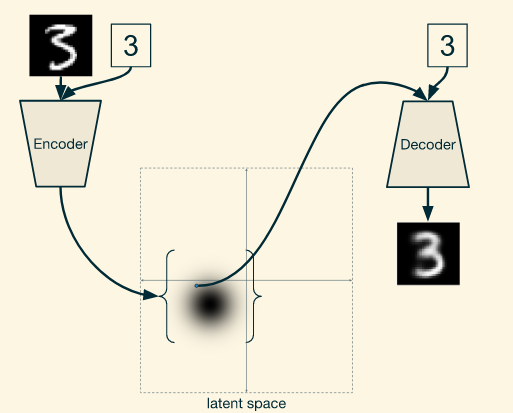
So, here the encoder part tries to learn q_φ(z|x,y), which is equivalent to learning hidden representation of data X or encoding the X into the hidden representation conditioned y. The decoder part tries to learn P_θ(X|z,y) which decoding the hidden representation to input space conditioned by y. The graphical model can be expressed as the following figure.

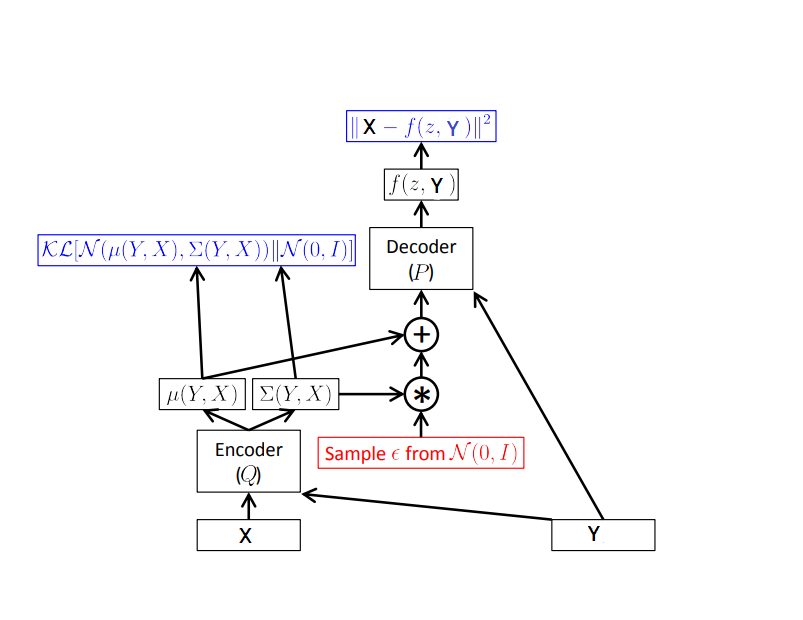
The neural network architecture of Conditional VAE (CVAE) can be represented as the following figure.

The implementation of CVAE in Keras is available here.